Lambdaと下げメーカーで機械学習モデルの構築を自動化
前回ローカルで実装していた学習モデル(勾配ブースティング)をAmazon SageMaker上へ移行し、ECRから自作のコンテナを呼び込むことで sagemaker.estimator.Estimator によるirisデータセットの訓練と推論サービスのデプロイを実験しました。今回は勾配ブースティングを用いた仮想通貨取引用の機械学習モデルを日次の仮想通貨データから再学習し推論サービスを更新する処理を行ってみます。MLOps(機械学習基盤版のDevOps)の文脈です。前回は自作コンテナを使用しましたが、scikit-learnはSageMaker Python SDKから利用できるためここでは素直にsagemaker.sklearn.estimator.sklearnを使用します。

記述したとおり開発した機械学習のモデル(Jupyter Notebookなどで開発したもの)を実運用するにあたって複数の問題が発生しています。※『機械学習プロジェクトの典型的な課題』ではより多くの項目が列挙されている
- 新しいデータ(日次)で機械学習モデルを再構築する手間がある
- 構築したモデルファイルの管理が面倒くさい
- 機械学習モデルがローカル環境でしか呼び出せない
前回の実装でクラウド上でAPIコールできる推論サービスをデプロイできるようになりましたが、依然として新しいデータに対する機械学習モデルの構築には手間がかかります。データの用意と加工、ライブラリを使用したモデルの訓練とモデルファイルの配置を手動で行っています。包括的な視点で見ると機械学習モデルの開発から実運用へ移行するにあたり以下を考慮しなければいけませんでした。
- 機械学習モデルの運用方法
- 推論サービスの提供方法
本稿では機械学習における環境構築から開発・運用や推論を幅広くカバーするAWSのマネージドサービスであるAmazon SageMakerとLambdaを使用して仮想通貨の分足から終値価格のラベリングを予測する機械学習モデルの訓練や推論サービスのデプロイを自動化してみたいと思います。クラウド上のモデル学習や推論サービスの提供は費用がかかることを除けばデメリットはそれほどないでしょう。
2019年のDevOps界隈ではMLOps(機械学習基盤版のDevOps)というトレンドで、機械学習モデルの管理やCI/CDの構築、ログ出力やモニタリングなどを自動化しワークフローなどへ乗せる流れがあるようです。[1]
機械学習チーム/開発チームは、最終的なソリューションの一機能となる機械学習モデルの作成とデリバリー(もしくはデプロイ)を自動化し、リリースサイクルを早める
- モデルの再利用とバージョニング
- モデルの挙動検証(テスト)とパフォーマンス検証
- モデルのデリバリー/デプロイ
- モデル実行のログ出力と分析
- モデル実行のモニタリング
SageMakerノートブックへの移行
SageMaker Python SDKを使用してSageMakerで用意されているコンテナを使用した訓練や推論サービスのデプロイが行えます。 SageMaker Python SDKをAmazon SageMakerのノートブックで読み込み、sagemaker.sklearn.estimator.sklearnのライブラリを使用することでscikit-learnを使用できます。今回はbitbank.cc APIで分足を取得し、標準のscikit-learnライブラリを使用するだけなので独自のコンテナは使用しません。
推論サービスのデプロイには model_fn の実装が必要ですが、APIのエンドポイントに対するリクエストの処理に以下のような関数を使用することも可能です。 predict_fn は推論の結果へさらに処理を加えて出力する場合には便利な関数です。
model_fn(model_dir): 訓練フェーズで保存されたモデルファイルを呼び出す関数です(必ず実装されているはず)input_fn(request_body, request_content_type): 入力データをパースしてdeserializeすることで、推論に対応するデータオブジェクトへ変換します、request_bodyはJSON/CSV/NPY形式であることが期待されています、この関数で各データ形式をNumpyへ変換してモデルへ引き渡します
# Picke形式と取り扱う場合
import numpy as np
def input_fn(request_body, request_content_type):
"""An input_fn that loads a pickled numpy array"""
if request_content_type == "application/python-pickle":
array = np.load(StringIO(request_body))
return array
else:
# Handle other content-types here or raise an Exception
# if the content type is not supported.
passpredict_fn(input_object, model): Deserializeされた入力を受けて、model_fnで読み込まれた推論を行い推論した情報を返します、例として以下のようにロジスティック回帰の分類確率を予測と一緒に返すことができます
# 予測結果と分類確率を出力する
import sklearn
import numpy as np
def predict_fn(input_data, model):
prediction = model.predict(input_data)
pred_prob = model.predict_proba(input_data)
return np.array([prediction, pred_prob])output_fn(prediction, content_type):predict_fnで出力された予測をcontent_typeでシリアライズされたバイト列にして返します、predict_fnからの戻り値であるpredictionはデフォルトでNumpyです、これをタイプに応じてJSON/CSV/NPYにシリアライズ可能です
SageMaker Python SDKのscikit-learnで使用されるReadTimePredictor がNumpyをNPYの形式にシリアライズします。推論サービスとしてデプロイされたモデルはNPY形式をdeserializeできるようになっています。[2]
Lambdaによる自動化の前に、以前に作成していた勾配ブースティングのモデル構築をSageMaker Python SDKを使用してSageMakerノートブックへ移植します。分足のOHLCVデータをbitbank.cc APIで取得してDataFrame形式からcsv形式へ変換しました。同時に upload_data を使用してS3へアップロードします。
SageMakerノートブックのローカルに保存されたOHLCVのデータです。最後の1, -1, 0が付与したラベル列(正解ラベル)となっています。最終列を正解ラベル列としています。

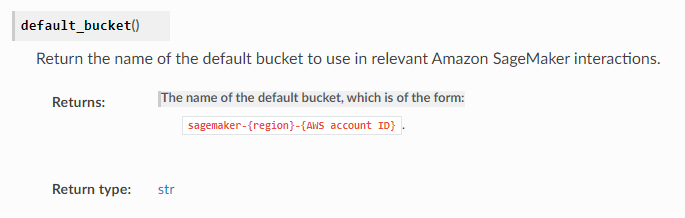
S3にアップロードされたcsvファイルです。バケットはデフォルトのバケットを使用しています。デフォルトのバケット名は sagemaker-<region>-<AWS account ID> で与えられます。[3]
本稿では特徴量の算出はせずに分足のOHLCVのままscikit-learnでモデル構築します(したがって正解ラベルの予測としては役立ちません)。sagemaker.sklearn.estimator.sklearnへ渡すトレーニングスクリプトは以下のようになりました。
トレーニングスクリプトをローカルから読み込んで fitでデータの訓練を行います。次に deploy で推論サービスのデプロイです。エンドポイントの名前を指定してデプロイしてください。Lambdaから更新する処理を行う際に、エンドポイント名を使用します。ここでは sagemaker-scikit-learn としています。
from sagemaker.sklearn import SKLearn
script_path = 'scikit_learn_gradient.py'# Initialise SDK
sklearn_estimator = SKLearn(
entry_point=script_path,
role = role,
train_instance_type="ml.c4.xlarge",
sagemaker_session=sagemaker_session,
output_path="s3://{}/output".format(sagemaker_session.default_bucket())
)print("Estimator object: {}".format(sklearn_estimator))# Run model training job
sklearn_estimator.fit({'train': train_input})# Deploy trained model to an endpoint
predictor = sklearn_estimator.deploy(initial_instance_count=1, instance_type="ml.m4.xlarge", endpoint_name="sagemaker-scikit-learn")
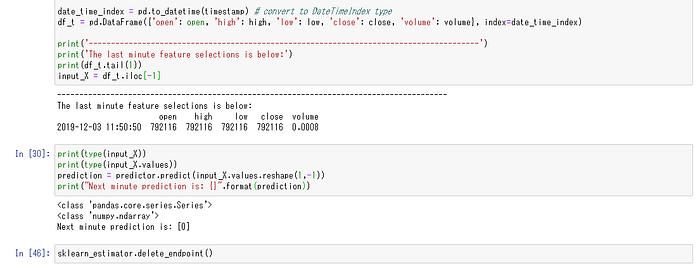
直近1分のOHLCVのNumpyデータを渡すことで推論サービスが予測ラベルを返してくれます。返りもNumpy形式です。以下の例では [0] が予測されました。1分後の終値は、予測に使用した閾値ほど価格は上昇も下降もしない、つまり売買しなくてよいという判断を導き出しています。これは昨日の1440分の分足から構築したモデルなので、翌日、もしくは定期的に過去24時間まで遡ったデータでモデルを更新することが理想的です。[3]
トレーニングスクリプトとSageMakerノートブックは以下のリポジトリにあります。[4]
Lambdaを使用したデプロイの自動化
SageMakerノートブック上へ機械学習モデルの構築を移植できました。独自のアルゴリズムや手法を使用したい場合は、自前のDockerコンテナをECR(Elastic Container Registry)へアップロードすることで呼び出せることを前回試しています。機械学習のモデルは1度構築して終わりではなく、一定期間ごとに訓練し更新していく必要があります。新しいデータからだけ最新のモデルを構築するケースもあると思いますし、過去一定期間のデータから遡って最新のデータも加えた上でモデルを更新するケースもあると思います。仮想通貨の分足から次点の価格の上昇・下降を予測するモデルの構築は前者のケースで、24時間分の分足から機械学習モデルを構築していました。推論サービスを提供する上では新しいデータによって再度モデルを構築し、推論サービスを上書き更新する必要があります。
推論サービスのデプロイを自動化するにはStep FunctionsやLambdaを使用できます。新しい機械学習モデルのファイルがS3に置かれたことをトリガーとして推論サービスのデプロイをキックすることが可能です。再訓練についてはCloudWatch Eventsのスケジューラを使用する、データがS3に置かれたイベントを検知するなどこちらも複数の方法が考えられます。
- Step Functionos — サーバレスサービスであるStep FunctionsでS3のモデルが更新されたかを確認する方法です。CloudWatch Eventsのスケジューラでステートマシンを呼び出し、モデル用のデータがあれば訓練を行い、推論サービスをデプロイします。サンプルの実装が既に存在します( https://github.com/aws-samples/serverless-sagemaker-orchestration)
- Lambda — Lambdaのイベント補足でS3に更新されたモデルが置かれたかを確認する方法です。CloudWatch Eventsのスケジューラで定期的に再訓練を行い新しいモデルをS3にPUTします。モデルがPUTされたイベントを検知して推論サービスを更新します。
以下の記事を参考にLambdaを使用した方法を実装しています。実装は同じではありません。[5]

まずはLambda関数を作成します。ここで作成するLambda関数の要件です。
- Lambdaの
eventがモデルの再トレーニングタスクであるretrainの場合はretrain_the_model()を呼び出します、CloudWatch Eventsのスケジューラでイベントを呼び出すことでトレーニングジョブの作成やモデルの再訓練に使用します - Lambdaの
eventがS3イベントであった場合にはhandle_s3_event(records['s3'])を呼び出します、これは推論サービスの再デプロイに使用します、retrain_the_model()のトレーニングジョブ実行のモデル保存によるS3のイベントを補足します
まずはLambda関数を作成しましょう。最新のサポート対象はPython 3.8のようです。3.7系しか使ったことはないですが、ここではPython 3.8を選択してみました。関数名を入力して関数を作成をクリックします。Lambda実行ロールのアクセス権限にはSageMaker FullAccessを追加で付与しています。権限は適切に設定してください。

作成したLambda関数へトリガーを追加します。SageMakerデフォルトのS3バケットに対するすべてのオブジェクト作成イベントに対するトリガーと、CloudWatch Eventsのスケジュールで毎時間となる rate(1 hour) によるトリガーを設定しました。スケジューラはcron形式やrate形式で指定できます。CloudWatch Eventsについては{“task”: “retrain”}を渡すことでLambda関数の retrain_the_model() を呼び出せることを想定します。


イベントを補足する lambda_handler は以下のようになりました。 event['Records']['s3'] で handle_s3_event(records['s3']) が、 event['task'] が retrain のときに retain_the_model() が呼び出されます。 retrain_the_model() は今回の例ではCloudWatch Eventsから呼び出します。
retrain_the_model() ではcreate_training_job を使用してトレーニングジョブの作成およびモデルファイルの作成を行います。Lambda関数の中ではSageMaker Python SDKを使用できないため、src_pathへ圧縮したトレーニングスクリプトを保存して呼び出す必要があります。トレーニングスクリプトはこれを圧縮して任意の場所へ保存しています。
Amazon SageMaker用のDockerイメージを指定しています。scikit-learnとSparkML用のAmazon SageMakerのDockerイメージの場所はこちらに記載されていました。[6]
トレーニングジョブが作成されて、モデルの構築が完了すると OutputDataConfig で指定したS3の場所へモデルファイルが保存されます。S3へのモデルファイルの保存のイベントを補足して handle_s3_event が呼ばれるようになっています。 jobidトレーニングジョブの名前で、モデルファイルの保存にこの名前を使用しているため、S3のパスから取得することができます。

S3のPUTイベントを補足して、モデルに使用されたトレーニングジョブIDから推論サービスの更新を行います。endpoint_nameは分かりやすい名前を使うことをお勧めします。これでLambda関数の作成は完了です。
CloudWatch Eventsのスケジューラから作成したLambda関数へJSONが送られるか、手動のテストイベントで動作を確認することができます。トレーニングジョブが作成され、モデルファイルがS3に保存されることで、エンドポイントの更新が走ります。

テストイベントはJSONで{“task”: “retrain”}を渡すだけの簡単なものです。作成したlambda_functionのコードはここに置いてあります。以上です。
AWSのマネージドサービスであるAmazon SageMakerとLambdaを使用した機械学習モデルの訓練や推論サービスのデプロイの自動化が行えました。ただしこの自動化はMLOps(機械学習基盤版のDevOps)の一部分であり、実際の運用ではさらに多くの項目の検討が必要でしょう。
- モデルの精度検証やパフォーマンスの確認
- 失敗した場合どうするか:S3は100%のデリバリを保証しない
- バッチ推論などその他機能のパイプラインへの組み込み
まとめ
- Amazon SageMakerは 機械学習モデルの構築、トレーニング、デプロイなどを提供するAWSのサービスである
- AWSのサービススタックの中で、MLサービスとして分類され、ラベリングやJupyter Notebookによる機械学習モデルの開発から、推論サービスのデプロイまでをフルマネージドで提供する
- TensorFlow、Apache MXNet、PyTorch、Chainer、Scikit-learn、SparkML、Horovod、Keras、Gluonなどのフレームワークをサポートしている
- MLOps(機械学習基盤版のDevOps)は、機械学習モデルの管理やCI/CDの構築、ログ出力やモニタリングの自動化など機械学習モデルの実装から運用までのライフサイクルを築くことである
- Amazon SageMakerの推論サービスのデプロイ自動化にはStep FunctionsやLambda関数などの方法を検討できる
Reference
- [1] MLOps(機械学習基盤)とは? AIOpsとの違い
- [2] Using Scikit-learn with the SageMaker Python SDK
- [3] 下げメーカーで機械学習モデルを推論サービスへ移行する ~AWS SageMaker with Docker image~
- [4] yuyasugano/scikit_learn_gradient
- [5] Start Your Machine Learning on AWS SageMaker
- [6] scikit-learnおよびSpark ML 用に構築済みのAmazon SageMaker Dockerイメージ
- [7] lambda_function.py
