仮想通貨の自動取引入門 ~Ta-Libによる特徴量の抽出と交差検証~
仮想通貨に限らず自動取引は取引時に人手を介さず、リスクをコントロールしつつコストの削減およびリターンを機械的に追求することであると考える。前回の記事では、分足のOHLCデータへ正解ラベルを付与し複数の機械学習アルゴリズムを適用した。本稿ではTa-Libを使用したテクニカル指標を機械学習の特徴量としてその相関関係を俯瞰し、特徴量の分析および層化抽出法を用いた交差検証によるモデルの妥当性を考察する。結論: OHLCVデータから7個のテクニカル指標を抽出することで構築したモデルは終値変化率の3値分類問題に対して極めて高い性能を示すことが判明した。

- 自動取引とは(再掲)
- OHLCの取得とデータ整形
- 正解ラベルとTa-Libを用いた特徴量の追加
- 教師あり機械学習によるモデリング
- 混合行列とROC曲線/AUC
- 結論と今後の方針
自動取引とは
金融商品における自動取引とはシステムトレードの非裁量取引を、特にプログラムを用いて自動化しまた定例化することでリスクのコントロールもしくはリターンの追求を省力化した上で達成することであると考える。
システムトレードやアルゴリズム取引という語には使用する組織や文脈に応じて複数の意味があること、また意味の混ざることがあるためにここでは単純に自動取引という用語のみ使用する。[1]
アルゴリズムを使用しないものも含め、自動取引という用語の意味はより広義に捉えて頂いて問題ない。プログラムを介して、取引機会を発見し、それを自動化しているものを自動取引と呼びたいと思う。非裁量性や高頻度取引(High Frequency Trading)など様々な利点のある自動取引であるが、まず大分類としてコストの削減を目指すものとリターンの追求を実現するものの2種類がある。[2]
- コストの削減
・取引コストの削減(執行系アルゴリズム、VAMPなどのベンチマーク系アルゴリズム)
・マーケット・メイクやバスケット取引などの定型的な業務の自動化による内部コストの削減
・マーケット・インパクトによるコストの削減
・最適な市場の選択をすることによる手数料の削減 - リターンの追求
・収益機会の発見(裁定アルゴリズム、ディレクショナル・アルゴリズムなど)
・リベートの獲得(メイカー・テイカー手数料)
・スプレッド収益の発見(マーケット・メイキング・アルゴリズム)
個人投資家についてはよほど大口でない限り、リターン追求のために自動取引を導入すると考えられることから、ここでは収益機会の発見を達成する自動取引をプログラムでどのように記述していくかを考えていく。主に裁定アルゴリズム、ディレクショナルアルゴリズム、マーケット・メイキング・アルゴリズムを個人投資家は利用する。自動取引に限らないが以下のPDCAを回して行くことで(自動取引においては自動的に行うことが好ましい)、効率よく収益機会の発見および収益の発生を実現することが理想である。
1.情報の収集および整理
2.自動取引と約定の確認
3.バックテスト(ベンチマーク)
OHLCの取得とデータ整形
OHLCとは(Open/High/Low/Close)の省略表記で、ローソク足の価格データセット(始値・高値・安値・終値)である。ここに出来高(Volume)を加え、OHLCVで提供されることも多い。
OHLCのデータは引き続きbitbank.cc APIから取得し、pandasを使用してデータ整形を行うこととする。pandasのデータフレームはインデックス付きの行列のデータ形式で、描画や機械学習・ディープラーニングの処理へそのまま活用できるデファクトスタンダードのライブラリである。
bitbank.cc APIの『Candlestick』を呼び出すことでローソク足の情報を取得できることが確認できた。

通貨ペア、期間、日付(年数)をパラメータとして渡すことができる。時刻はUNIX時間であり、指定した日付の朝9:00からのデータが返却されることが確認できた(UTC 0:00からのデータ)。
指定した日付のOHLCデータを取得し、csvとして保存するコードをgithubへアップロードしている。今回は分足を使用するため期間を1minに設定する。
2019/9/1の分足を対象としてデータを取得した。 volume もDataFrame計算へ加え、1440行、5列となっている。以下のようにして volume をDataFrameへ加えることができる。
df = pd.DataFrame({'open': open, 'high': high, 'low': low, 'close': close, 'volume': volume}, index=date_time_index)コードを実行すると以下のような結果が得られる。
$ pipenv install --dev
$ pipenv run start
open high low close volume
2019-09-01 00:00:00 1020201 1020201 1020201 1020201 0.0001
2019-09-01 00:01:01 1020201 1020201 1020201 1020201 0.0000
2019-09-01 00:02:02 1020201 1020201 1020201 1020201 0.0000
2019-09-01 00:03:03 1020201 1020201 1020201 1020201 0.0004
2019-09-01 00:04:04 1020200 1020478 1020200 1020478 1.0640新規にpipenvプロジェクトを始める場合は以下のライブラリを導入する必要がある。
pipenv --python 3.7.3
pipenv install --dev requests numpy pandas
pipenv install --dev Ta-Lib backtesting scikit-learn
pipenv install --dev git+https://github.com/bitbankinc/python-bitbankcc.git#egg=python_bitbankcc次に正解ラベルを定義し、DataFrameの各行における正解をラベリングしていく。正解ラベルについては前回と同じものを使用する。
正解ラベルと特徴量の追加
分足におけるある特定の行の特徴量から次点(次の分足)のcloseが上昇するか下降するか、もしくはその中間という風に3値のラベルへ分類した。前提を再確認する。[3]
- 1日分の分足(1440行)から現在の次点のcloseが上昇するか下降するかを予測する
- 1分後の分足のcloseの値からの変化率が特定のある定数を上回っている場合に『1』、下回っている場合に『-1』、そうでない場合に『0』というラベルを与える(3値の分類問題とする)
- 変化率は正規分布に従うものと仮定する(選択した定数における変化率の形は鐘形だが、正規分布ではないようであった)
正解ラベルの与え方は前回と同様である。dfはbitbank.cc APIから取得した分足のOHLCデータを引き続き使用している。df_へ学習データと計算した正解ラベルをまとめた。 pct_change(1) によって間隔1(1分の行)の差分を計算できるが、対象の行に格納される計算はその行と1行前の行との差であるため shift(-1) を使用して行を1段引き上げている(つまり現在時点の行における1分後のcloseからの変化率を知りたいため、1行ずれていると考えた)。
lambda関数でラベルの付与の計算を指定しているが、ここでは変化率が0.01%(0.0001)以上である場合に『1』、-0.01%(-0.0001)以下の場合に『-1』、その間であるときに『0』というラベルを与えている。yに変化率を、y_にラベル付けしたDataFrameを格納する。
今回は特徴量としてopen/high/low/closeは一切使用せず、OHLCのデータから計算できるテクニカル指標とボリューム、および pct_changeで計算した変化率を選出する。Open/High/Low/Closeの値自体は正解に対する相関が薄いと考えれるので本稿では使用しない。
テクニカル指標の計算にはTa-Libを使用した。Ta-Libはテクニカル指標を計算する関数群が10種類あり、それぞれに相当数のテクニカル指標がグルーピングされていることが確認できる。[4]

この中からトレーダーに比較的よく使用されると思われるテクニカル指標を特徴量として計算した。相関分析や特徴量エンジニアリングで特徴量をプルーニング(剪定)することを後に考える。採用したテクニカル指標は以下の通りである。
- EMA(Exponential Moving Average) — 決められた期間を現在から遡った終値平均値(EMAでは直近の終値を重視する計算)でここでは3分間の指数平滑移動平均を採用している
- Momemtum — 相場の勢いや方向性を判断するオシレータ系指標で、ここでは5分前の終値を採用している
- RSI(Relative Strength Index) — 相場の過熱感を一定期間の終値から計算するオシレータ系指標で、14分間のRSIをここでは採用している
- ADX (Average Directional Movement Index)— DI+とDI-と共にそのトレンドを参考とするオシレータ系指標で、J.W.ワイルダー氏のパラメータを参考としn=14を使用、ただしここではさらに前の分足からの変化率を採用している
- AD(Chaikin A/D Line)—価格変化と出来高の変化から計算できるオシレータ系指標で、分足を利用した値を採用している
上記5個に加え元からある分足のボリュームと終値の変化率の計7個の特徴量の相関関係をSeabornのpairplotで描画した。matplotlibではパレット表から色の指定方法を確認できる。[5]
# seaborn plot
import seaborn as sns
df_ml = X_.join(y_)
print(df_ml.dtypes)
print(df_ml['y'].value_counts())
sns.pairplot(df_ml, hue='y', vars=['volume', 'diff', 'ema', 'momentam', 'rsi', 'adx', 'ad'], palette={1: 'gray', 0: 'brown', -1: 'darkorange'})
次にSeabornのheatmapで各特徴量の相関係数を表示した。emaとadには正の相関が見られるが、両指標は価格変化が影響を与えるためにこの結果は自明である。その他に強い相関関係の見られるものはない。
# heatmap plot
fig = plt.figure(figsize=(15, 15))
ax = fig.add_subplot(1, 1, 1)
sns.heatmap(X_.astype(float).corr(), vmax=1.0, square=True, linecolor='white', annot=True, ax=ax, cbar=False)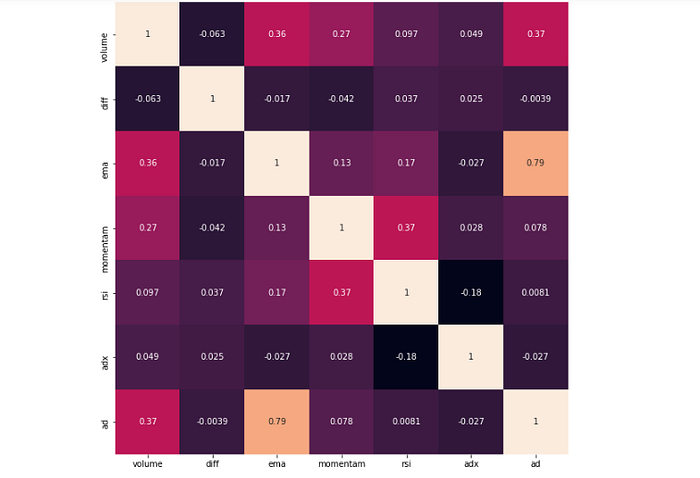
Seabornの使い方は以下のブログを参考にした。[6]
教師あり機械学習によるモデリング
OHLCVのデータを特徴量であるテクニカル指標に加工すること、およびOHLCVデータから正解データのラベリングを行ってきた(正解データのラベリング方法は前回と全く同様である)。前回同様に機械学習のライブラリであるscikit-learnを使用して説明変数X_のデータと被説明変数y_のデータを分類アルゴリズムを用いて学習させていく。
scikit-learnからライブラリとして使用できる4つのアルゴリズムを選択した。また引き続きパラメータ調整やグリッドサーチによる最適なパラメータの探索は行わない。評価は精度スコアとf1スコアを確認する。
- k近傍法
- ロジスティック回帰
- ランダムフォレスト
- 勾配ブースティング
X_とy_に格納されているデータを訓練用(モデル学習用)とテスト用(モデル評価用)へと分割し、各アルゴリズムを用いて学習させた結果が以下である。ここでTrainと表記のあるスコアについては訓練したモデルに対してX_trainとy_trainから計算したスコア、Testと表記のあるものについては同じモデルに対してX_testとy_testから計算したスコアを表している。テストデータでの結果をみると勾配ブースティングのモデルが10割の正答率となっている。
多値分類問題(ここでは3値分類問題)におけるf1スコアは各ラベルごとのf1スコアを求めてから、f1スコアの平均を計算するマクロ平均と、厳密な計算に基づくマイクロ平均がある。さらにマクロ平均には平均計算を行う際に実正解ラベルの比率に基づいた重み付き平均をとる方法がある。[7]
前回は重み付き平均を採択したが、ラベル『0』が多いことを考えると最適な手法とは言えない。そのため今回はf1スコアの計算をマイクロ平均へと変更している。
X_train shape: (964, 7)
X_test shape: (476, 7)
y_train shape: (964, 1)
y_test shape: (476, 1)
KNN Train Accuracy: 0.922
KNN Test Accuracy: 0.859
KNN Train F1 Score: 0.922
KNN Test F1 Score: 0.859
Logistic Train Accuracy: 0.951
Logistic Test Accuracy: 0.947
Logistic Train F1 Score: 0.951
Logistic Test F1 Score: 0.947
RandomForest Train Accuracy: 1.000
RandomForest Test Accuracy: 0.998
RandomForest Train F1 Score: 1.000
RandomForest Test F1 Score: 0.998
GradientBoosting Train Accuracy: 1.000
GradientBoosting Test Accuracy: 1.000
GradientBoosting Train F1 Score: 1.000
GradientBoosting Test F1 Score: 1.000コードは以下の通りである。
注意が必要な点として、この結果は3値分類問題への正答率であるということである。ラベル『0』とした変化率への正答率も含まれており、このラベルがデータに占める割合が最も多い。1440の分足のうち1092個はこのラベル『0』である。したがって残りの348個の分足が次点の価格が上昇するか下降するかを示唆していることになる。次に各モデルにおけるテストセットに対する混合行列とROC曲線/AUCからこの結果について考察する。
混合行列とROC曲線/AUC
機械学習のモデリングによって終値の変化率の3値分類問題に対する高い正答率を得られたが、このモデルは汎化していない可能性が高い(このテストセットに対してToo good to be true)。そこで混合行列やROC曲線/AUCを考察し、さらにこの精度が信頼できるものかどうか確認するために交差検証を追加で実施する。
テスト用(モデル評価用)のデータセットを使用して混合行列を描いた。ロジスティクス回帰はラベル『0』という予測に対して、実際は上昇や下降といったFalse Positive(偽陽性)があることがスコアを押し下げる理由となっていることが見て分かる。アンサンブル学習のランダムフォレストや勾配ブースティングは精度が非常に高く、52件あるラベル『-1』および68件あるラベル『1』に対する予測も含め100%に近いスコアである(ここでX_とy_についてそれぞれ訓練用データセットが計964件、テスト用データセットが計476件あり、この結果はテスト用データセットに対する予測結果であることを確認しておく)。
from sklearn.metrics import confusion_matrix
fig = plt.figure(figsize=(15, 15))for (i, pipe) in enumerate(pipe_lines):
predict = pipe.predict(X_test)
cm = confusion_matrix(y_test.values.ravel(), predict, labels=[-1, 0, 1])
ax = fig.add_subplot(2, 2, i+1)
ax.set_title(pipe_names[i] + ' Confusion Matrix')
sns.heatmap(cm, square=True, linecolor='white', annot=True, ax=ax, cmap="Reds", cbar=False, fmt='d', linewidths=.5, xticklabels=[-1,0,1], yticklabels=[-1,0,1])
f1スコアは適合率(Precision)と再現率(Recall)のスコアの調和平均で求められる。適合率はTPR(True Positive Rate)・真陽性率とも呼ばれ、これを縦軸にFPR(False Positive Rate)・偽陽性率を横軸に取る平面上のグラフをROC曲線と呼ぶ。その曲線下の面積がAUC(Area Under the Curve)であり、その面積の最大値は1.0である。ROC曲線についての詳細は割愛するが、分類正答率が10割である場合には、AUCは1.0となる。
ROC曲線は通常二値分類問題に使用されるが、scikit-learnでは多値問題についても二値化(バイナライズ)してラベルごとにROC曲線を描くことができる。以下は、構築した勾配ブースティングのモデルを使用してテスト用データセットから予測した結果のラベル『1』に対するROC曲線で、AUCは1.0であった(つまらない結果晒してすいません(-_-;))。[8]

最も性能のよかった勾配ブースティングを用いて、層化抽出法による10分割交差検証を行う。sciki-learnで交差検証を行う際には層化抽出法の実装されたStratified K-Fold CVを使用する。
元のデータセットを1通りの訓練用とテスト用データセットへ分割するだけでなく(これはホールドアウト検証と呼ばれる)、K個にデータセットを分割し、1つをテスト用に残りのK-1個を訓練用に使用してK回学習させる手法がK分割交差検証である。また汎化能力を正しく評価するためには、被説明変数のラベルの偏りが少なくなる層化抽出法によるK分割交差検証を使用したほうがよい。[9]
ここではK分割交差検証のK回の結果(10回)を相加平均した値を出力している。今回構築した勾配ブースティングのモデルを使用して99.9%以上のラベル分類の正答率が得られた。
from sklearn.model_selection import cross_val_score, StratifiedKFold
cv = cross_val_score(pipe_gb, X_, y_.values.ravel(), cv=StratifiedKFold(n_splits=10, shuffle=True, random_state=39))
print('Cross Validation with StratifiedKFold mean: {}'.format(cv.mean()))Cross Validation with StratifiedKFold mean: 0.9993055555555556
結論と今後の方針
前回使用したOpen/High/Low/Closeの値自体は正解に対する相関が薄いと考え、今回は説明変数としてテクニカル指標を使用した。結果、2019/9/1におけるOHLCVデータから7種のテクニカル指標を特徴量を抽出することで構築した勾配ブースティングのモデルは、3値分類(終値の変化率上下0.01%に対して設定した3種のラベル)に対して極めて高い性能を示すことが分かった(99.9%以上)。
今回もパラメータ調整やグリッドサーチによる最適なパラメータの探索は行っていない。調整できる点としてはパラメータだけでなく、テクニカル指標に使用したn値などの各値や次元削減などの変数の変換である。より洗練されたスタッキングなどの手法も検討したい。
ただし限定的な条件下だが、上記のような調整をしなくとも既に高い性能を持つモデルとなっているように見える。そのためこの分類器を実運用しつつ、次のような改善を2点行っていきたいと考えている。
- 3値分類ではなく分足から上昇/下降のみを分類する2値分類のモデルへ変更する
→いままで見てきたとおり終値の変化率にしきい値を設けるやり方では変化率の少ないラベル『0』が多いため取引機会が限定されてくる、1日は1440分であるが1000個以上がこのラベル『0』であるため実質的に機会損失である(1分後の終値が同値のケースを考慮する必要あり) - Pubnubを使用したリアルタイムなデータに反応する分類器を構築する
→現在のモデルではOHLCVのデータをAPIなどで毎分取得する必要があり、その際の取引機会の数は最大化できたとして1日1440回(1440分)である、未計測ではあるがPubnubによるリアルタイムなストリームのほうが1日当たりの配信データ本数は多いはずである
今回実装したコードは以下のリポジトリへ保存した。[10]
https://github.com/yuyasugano/ml-classifier-Ta-Lib-ohlc/
以上、次回以降はスタッキングやPubnubを活用した機械学習の手法について取り上げていきたい。
Reference
- [1] システムトレード
- [2] NTTデータ・フィナンシャル・ソリューションズ — アルゴリズム取引の正体
- [3] 仮想通貨の自動取引入門 ~機械学習を用いたOHLCデータの3値分類問題化~
- [4] Ta-Lib — Supported Indicators
- [5] List of named color — Matplotlib
- [6] Python, pandas, seabornでペアプロット図(散布図行列)を作成
- [7] 分類タスクの評価指標の解説とsklearnでの計算方法
- [8] Receiver Operating Characteristic (ROC)
- [9] 層化抽出法を使ったK-分割交差検証 (Stratified K-Fold CV)
- [10] yuyasugano/ml-classifier-Ta-Lib-ohlc
